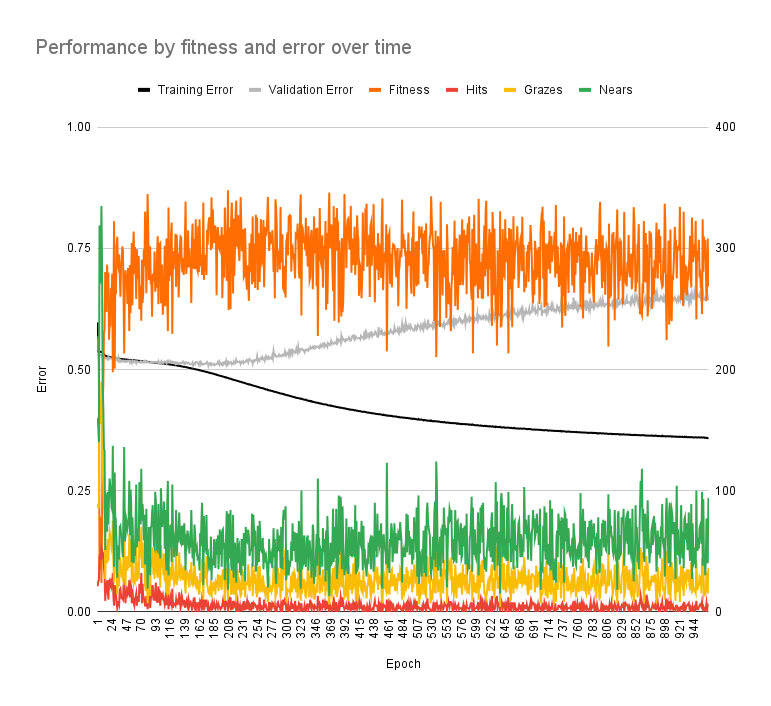
- neural network is trained with deep Q-learning in its own training environment
- controls the game with twinject
demonstration video of the neural network playing Touhou (Imperishable Night):

it actually makes progress up to the stage boss which is fairly impressive. it performs okay in its training environment but performs poorly in an existing bullet hell game and makes a lot of mistakes.
let me know your thoughts and any questions you have!