1
No Stupid Questions (Developer Edition)
14 readers
1 users here now
This is a place where you can ask any programming / topic related to the instance questions you want!
For a more general version of this concept check out !nostupidquestions@lemmy.world
Icon base by Lorc under CC BY 3.0 with modifications to add a gradient
founded 2 years ago
MODERATORS
2
3
4
5
6
7
8
9
Hello. I have Windows - Ubuntu dual boot and I'm trying to move space from Windows to Ubuntu. I've already freed space from the Windows side
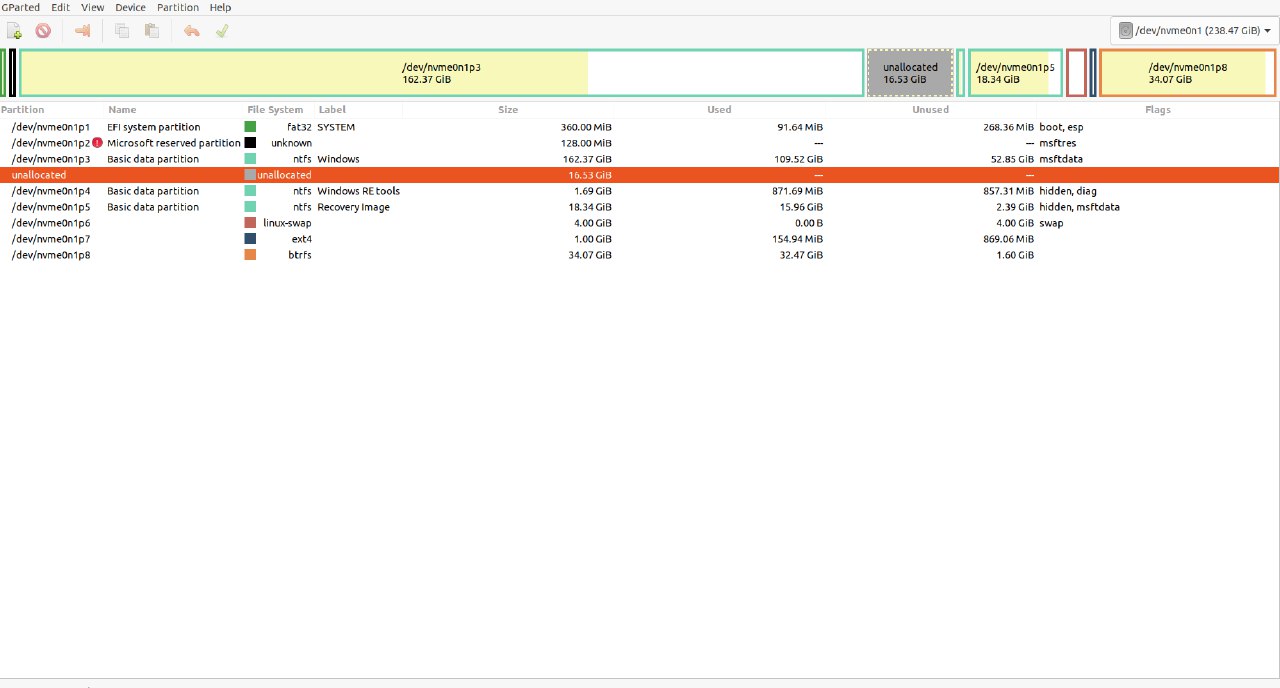
I'm pretty sure that I've read online that it can be dangerous to move the unallocated partition, because next boot to windows can corrupt my Ubuntu system. Is it true? Also, when I'm trying to move the unallocated partition, there's no option to "move/resize", so I swap them with the next following partition one by one. Is it the right way to do it?
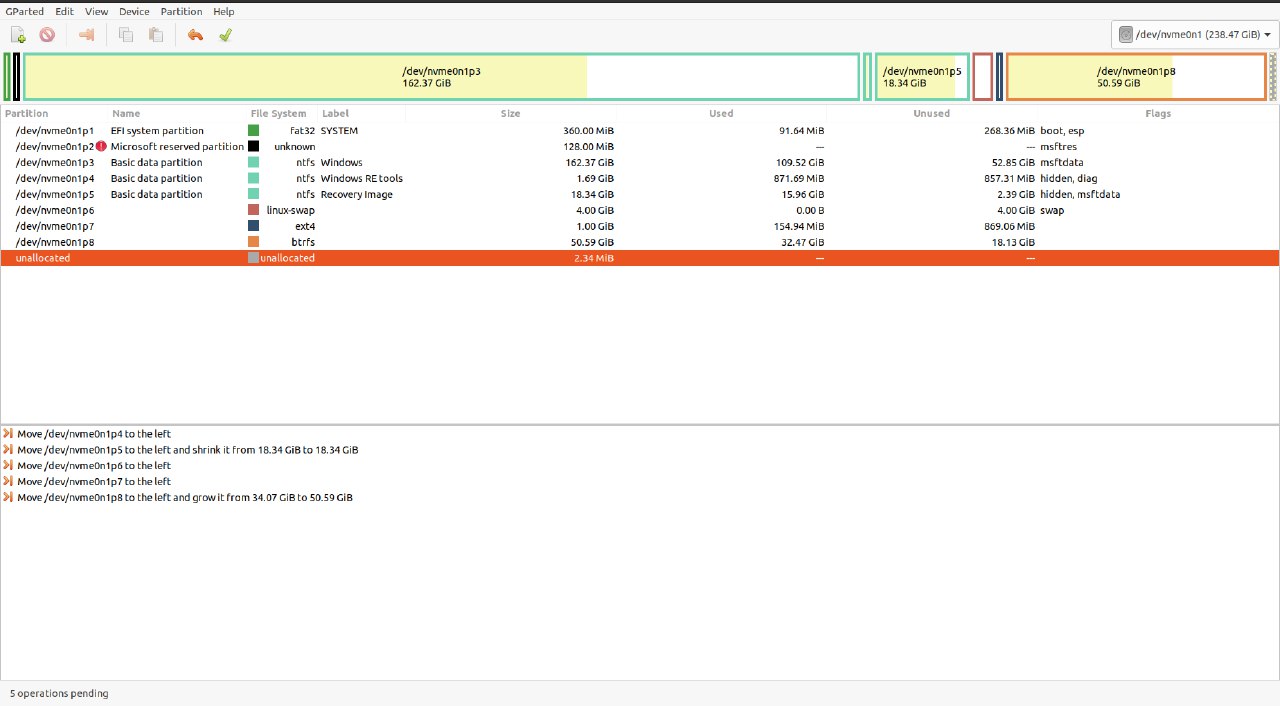
10
11
12
13
14
15
16
17
2
PyQt vs Kivy, which one has better syntax for someone learning a framework from 0?
(lemmy.dbzer0.com)
18
19
20
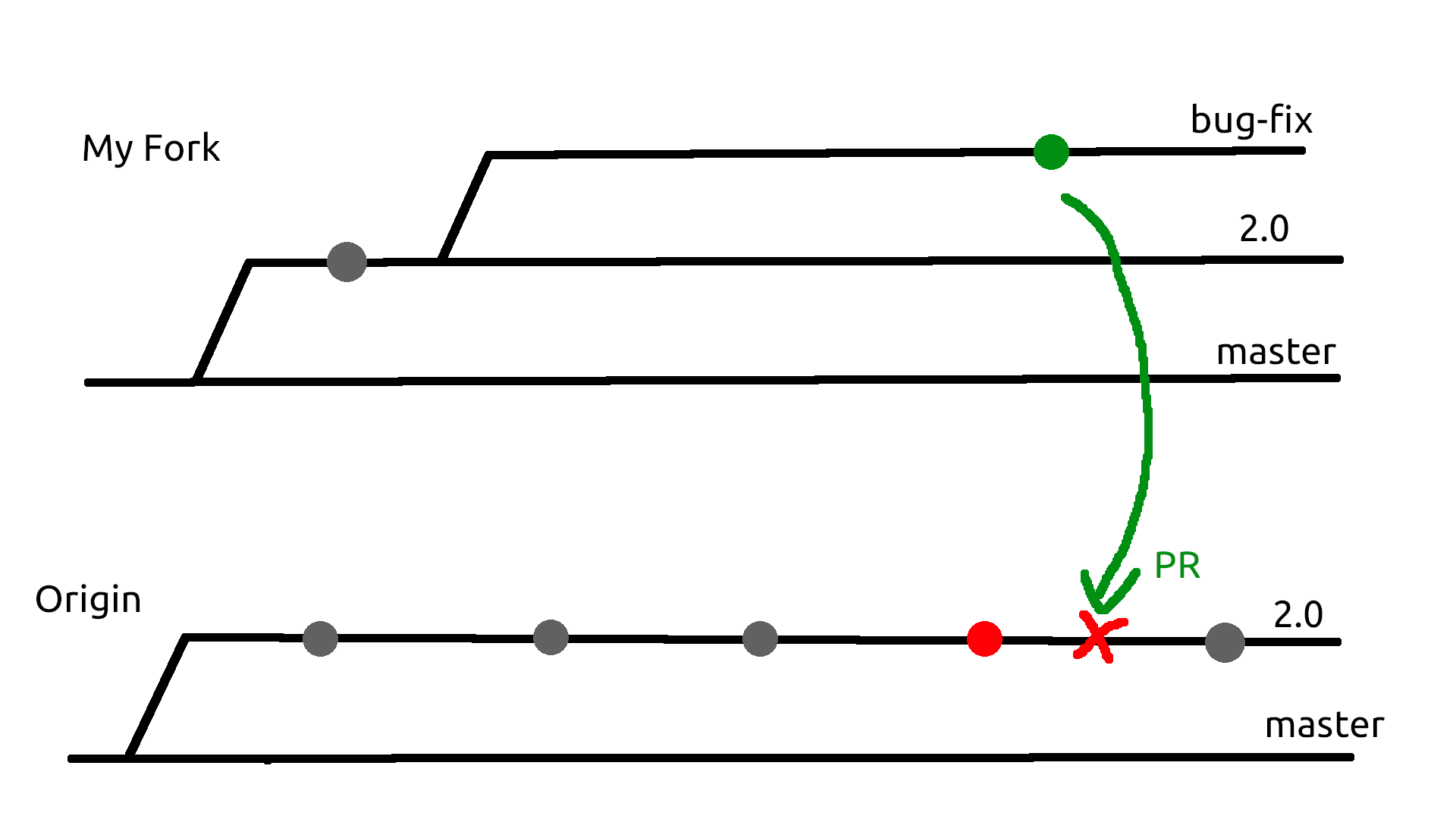
So I have a bug fix (green) and owner also made a bug fix (red) but I would like to rework both of them due to discussion we had. I have opened a PR and there is merge conflict that can't be resolved. Should I open a new branch in my fork and close PR or should I google some rebase magic to apply commits to my bug-fix branch.
21
22
23
24
25
view more: next ›