this post was submitted on 07 Apr 2024
265 points (100.0% liked)
Security
113 readers
1 users here now
Confidentiality Integrity Availability
founded 4 years ago
MODERATORS
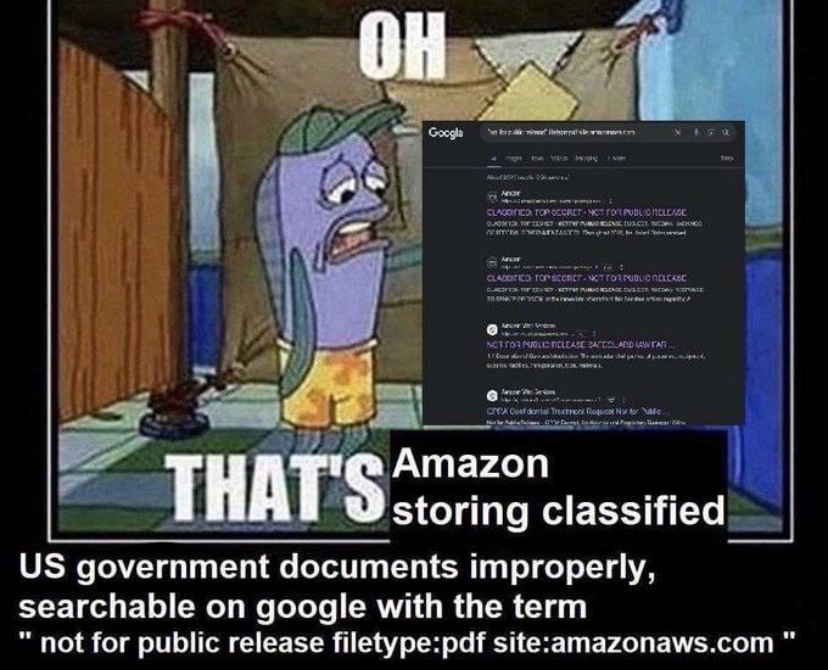
you are viewing a single comment's thread
view the rest of the comments
view the rest of the comments
There's no reason for amazonaws.com to be on search engine at all. Which is just as simple as placing a robots.txt with deny all declaration. Then no user would have to worry about shit like this.
Who said that?
Many other customers instead want to get that, maybe they are hosting images for their website on S3, or other public files that are meant to be easily found
If the file isn't meant to be public, then it's the fault of the webmaster which placed it on a public bucket or linked somewhere in a public page
Also: hosting files on Amazon S3 is super expensive compared to normal hosting, only public files that are getting lots of downloads should be using that. A document that's labeled for "internal use only" should reside on a normal server where you don't need the high speed or high availability of AWS and in this way you can place some kind of web application firewall that restricts access from outside the company/government.
For comparison, it's like taking a $5 toll road for just a quarter of mile at 2 am. There's no traffic and you're not in hurry, you can go local and save that $5
There's also the question of what happens if they just ignore the robots.txt file
robots.txt doesn't have to be followed. It doesn't block crawling.