Been working on this for a couple hours. I did a lot of cleanups etc. either in GIMP or with img2img
The model is Dark Sushi Mix 2.5D. I absolutely love using that model!
In the prompt you'll notice "a photo of Anastasia Jubilianne." and "wearing modest Morassen sect priestess dress." These are things that don't really exist, but I find using names like this tends to produce more consistent results.
Settings are: (masterpiece, best quality, high quality, realistic:1.1), (vibrant colors, vivid colors, Diffused lighting:1.1)
priestess, silky long black hair, deep blue eyes, (large breasts:1.2), huge breasts
a photo of Anastasia Jubilianne.
determined, slightly afraid
exploring a dungeon, exploring a cave system, slightly dark, light magic, soft light hue, holding_staff
holding a fantasy gold-laden cross shaped staff that emits light, staff decorated by a single circle up top
modest clothing, black clothing
wearing modest Morassen sect priestess dress, black conservative clothing Negative prompt: easynegative, cartoon, anime, deformed, girl, complex, bad-hands-3, (cleavage:1.2), naked, pelvic_curtain, sideboob, earrings Steps: 35, Sampler: DPM++ 2M Karras, CFG scale: 6, Seed: 3293703088, Size: 512x512, Model hash: 2d0010aca5, Model: darkSushi25D25D_v20, Denoising strength: 0.45, Clip skip: 2, Hires upscale: 2, Hires steps: 22, Hires upscaler: R-ESRGAN 4x+

Fairly close xD
You have to download the Dark Sushi Mix 2.5D model from civitai to get same results. The base SD model is not really good at generating much of anything.
also download the add_detail lora, but that one is not as needed. Just adds a bit more details
Oh, also copy paste my whole generation settings and hit the button below. It will copy my settings (but not the models you have to download that):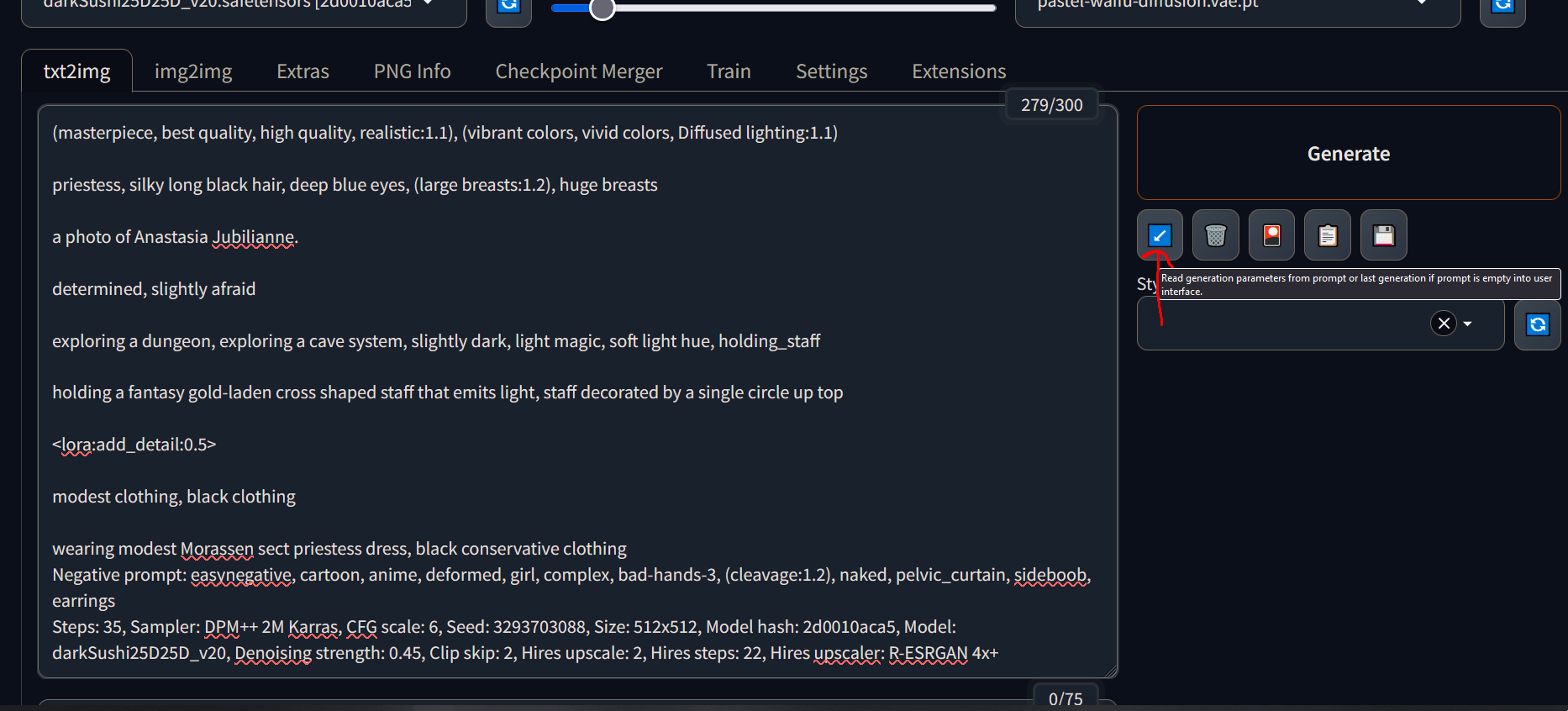
Of particular importance in models like dark sushi is using the Clip Skip 2 setting. My generation settings will set that for you in the overrides, but keep it in mind for the more "anime" models. This setting generates better results simply because a lot of anime models were trained with the clip skip 2, which I believe governs how in depth a concept the text encoder explores.