It's about asking, "how does this algorithm behave when the number of elements is significantly large compared to when the number of elements is orders of magnitude larger?"
Big O notation is useless for smaller sets of data. Sometimes it's worse than useless, it's misguiding. This is because Big O is only an estimate of asymptotic behavior. An algorithm that is O(n^2) can be faster than one that's O(n log n) for smaller sets of data (which contradicts the table below) if the O(n log n) algorithm has significant computational overhead and doesn't start behaving as estimated by its Big O classification until after that overhead is consumed.
#computerscience
Image Alt Text:
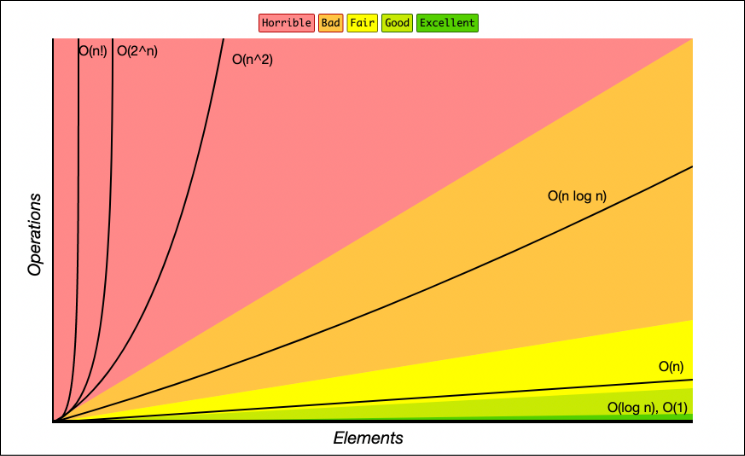
"A graph of Big O notation time complexity functions with Number of Elements on the x-axis and Operations(Time) on the y-axis.
Lines on the graph represent Big O functions which are are overplayed onto color coded regions where colors represent quality from Excellent to Horrible
Functions on the graph:
O(1): constant - Excellent/Best - Green
O(log n): logarithmic - Good/Excellent - Green
O(n): linear time - Fair - Yellow
O(n * log n): log linear - Bad - Orange
O(n^2): quadratic - Horrible - Red
O(n^3): cubic - Horrible (Not shown)
O(2^n): exponential - Horrible - Red
O(n!): factorial - Horrible/Worst - Red"
I don't agree that it's useless or misguiding. The smaller dataset, the less important it is, but it makes massive difference how the rest of the algorithm will be working and changing context around it.
Let's say that you need to sort 64 ints, in a code that starts our operating system. You need to sort it once per boot, and you boot less frequently than once per day, in fact you know instances of the OS that have 14 years of uptime, so it doesn't matter at all right? Welp. Now your OS is used by a big cloud provider and they use that code to boot the kernel 13 billions times per day. The context changed, time passed by, your silly bubble sort that doesn't matter on small numbers is still there.
Except the point of this post is that a different sort with worse Big O could be faster with a small dataset.
The fact that you're sorting those 64 ints billions of times simply doesn't matter. The "slower" sort is still faster in practice.
That's why it's important to realize that Big O notation can be useless for small datasets. Because it can actually just be lying to you.
It's actually mathematical. Take any equation:
y = x^2 + xFor large x the squared term dominates. The linear may as well not exists. It's O(x^2). But when x is below 1? Well suddenly that linear term is the more important one! Below 1 it's actually O(x) in practice.